Artificial intelligence on Apple devices does not operate in isolation from the rest of the chip. It is embedded into the silicon architecture itself. When Apple introduced the Neural Engine with the A11 Bionic chip, it marked a turning point. That first version featured a dual-core Neural Engine capable of performing hundreds of billions of operations per second. At the time, this was presented as groundwork for machine learning features that would expand over years.
As A-series chips progressed, Apple significantly increased Neural Engine capacity. Later generations moved to eight cores and eventually to a sixteen-core configuration. That sixteen-core structure has remained consistent across several recent A-series and M-series chips. However, stability in core count does not imply stagnation. Each generation has improved throughput, efficiency per watt, and internal data flow, allowing the same nominal core count to deliver stronger real-world performance.


How Neural Core Counts Scale Across Chips
Core scaling in Apple silicon follows a measured strategy. Instead of continually increasing the number of neural cores, Apple refined architecture and integration. In A-series chips powering iPhone models, the sixteen-core Neural Engine focuses on short, high-intensity bursts of AI computation. These include facial recognition for secure authentication, computational photography processes such as Smart HDR stacking and subject segmentation, predictive typing, Live Text recognition, and speech processing.
In this mobile context, power efficiency matters as much as raw speed. Neural operations must complete in milliseconds without overheating the device or draining the battery. As a result, Apple optimizes neural cores to deliver high operations per second within strict thermal limits.
M-series chips used in Mac systems also feature a sixteen-core Neural Engine, but the surrounding architecture changes the equation. Unified memory design allows CPU, GPU, and Neural Engine to access the same memory pool. With higher memory bandwidth and larger RAM configurations, Mac systems can handle heavier AI workloads over longer periods. Tasks such as large language model inference, advanced video enhancement, and professional audio transcription benefit from this sustained capability.
Although both iPhone and Mac may list sixteen neural cores, their effective performance differs because of system context. A MacBook with expanded unified memory and greater thermal capacity can sustain AI tasks at higher throughput levels than a smartphone designed for compact efficiency.
What Neural Scaling Means for AI Workloads
The presence of dedicated neural cores shifts how AI features are delivered. Instead of relying entirely on cloud processing, many machine learning tasks now execute directly on-device. This reduces latency and improves privacy, as data does not need to be transmitted externally.
Core count scaling influences which AI workloads can be handled locally. For example, lightweight inference tasks such as voice recognition or image classification run comfortably on iPhone Neural Engines. More complex generative models may leverage both Neural Engine acceleration and GPU parallelism, especially on Mac systems with expanded resources.
Importantly, Apple’s strategy suggests that AI performance growth is not dependent solely on increasing neural core numbers. Architectural refinements, improved instruction pipelines, enhanced memory bandwidth, and software-level optimization all contribute to performance scaling. In some cases, a newer chip with the same sixteen-core Neural Engine significantly outperforms an older one because of internal efficiency gains.
Neural cores do not replace CPU or GPU computation. Instead, they form part of a coordinated processing system. AI workloads often move between subsystems depending on task requirements. The CPU may handle orchestration and logic control. The GPU may process parallel numerical operations. The Neural Engine accelerates specialized inference stages. This division of labor allows Apple devices to balance speed and energy efficiency effectively.
As AI features become more integrated into daily workflows — from camera pipelines to language assistance and contextual prediction — neural core scaling shapes device longevity. A device’s ability to support future AI-driven updates depends partly on the capability of its Neural Engine. Apple’s approach of maintaining a stable core count while increasing architectural efficiency suggests a long-term strategy focused on balanced performance rather than headline escalation.
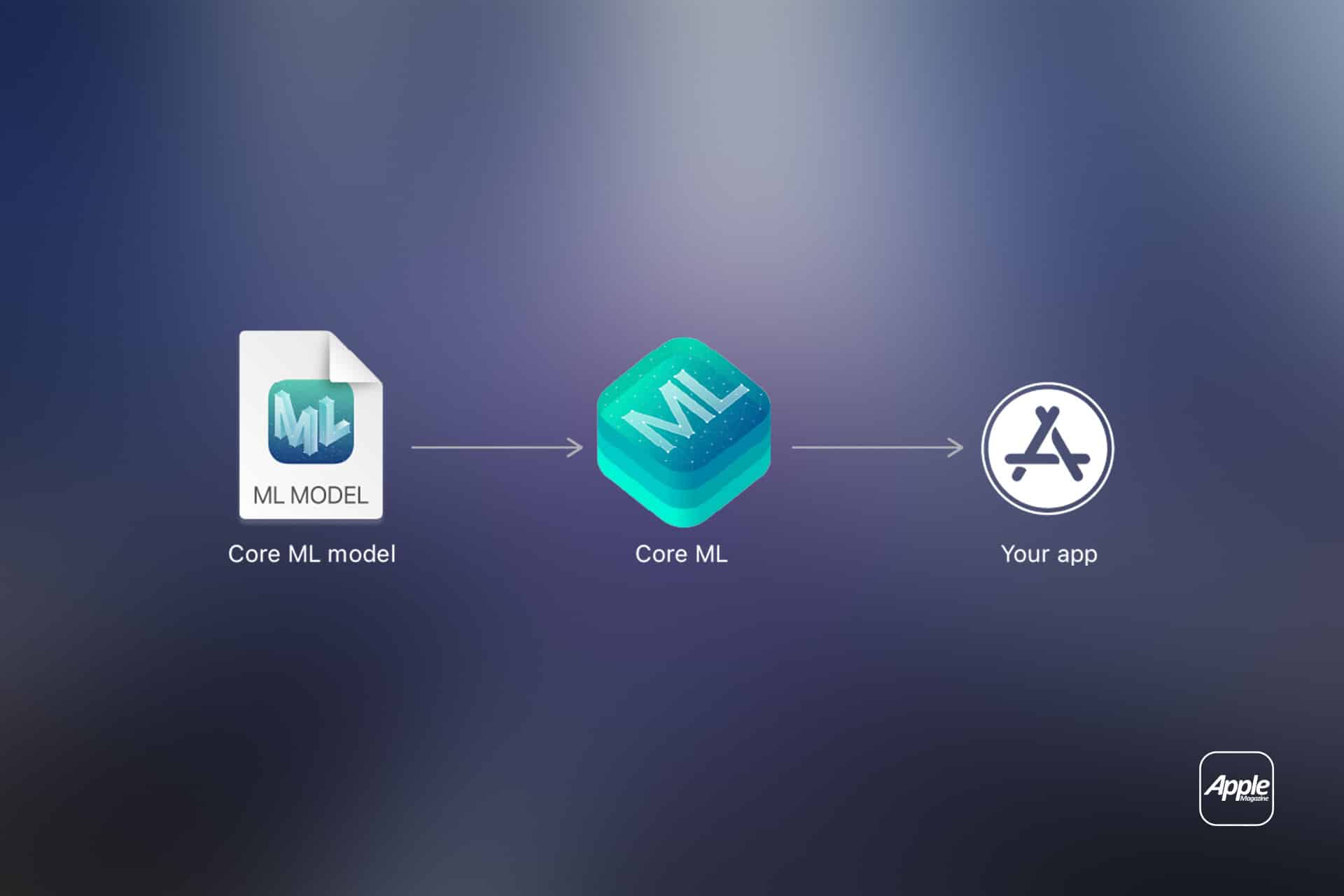
Understanding Apple neural cores requires examining the broader chip ecosystem. Core counts provide a structural reference point, but sustained AI capability emerges from the interaction between neural acceleration, unified memory, system bandwidth, and software frameworks such as Core ML. As machine learning tasks grow more sophisticated, this integrated design determines how effectively devices adapt across generations.